How to Sync Runkeeper and Strava

I have ten years of running data on Runkeeper but it seems like every runner I know uses Strava instead. I mean gee, I was here first and all that.
Runkeeper works for me and I’m the loyal type, so whilst I could export all my data and switch over to Strava, it would be nice to be able to use both, keeping my exercise data in sync and – let’s be honest here – humblebragging about my runs to all my friends on Strava.
My aim is to record my activities in Runkeeper, then have them appear in Strava automatically. My first instinct was to look up API documentation for both apps, with a view to writing a simple connector that would log runs to Strava from Runkeeper.
Unfortunately, Runkeeper seem to have withdrawn public access to their APIs and all lingering links I could find to the documentation redirected to their homepage. It did however seem like existing apps were able to interface with Runkeeper, so here’s the route I picked:
- Connect Zapier to my Runkeeper account.
- Create a ‘Zap’ to pass data from each Runkeeper activity to a custom app.
- Transpose the data into GPX format and load it into Strava via their API.
In addition, I’ll write a script to import all of my historical data into Strava from Runkeeper export files (which are already in GPX format).
Connecting Zapier to My Runkeeper Account
Zapier have an integration with Runkeeper that receives data about exercise activities whenever a new one is created. My plan was simply to send this data over http to my custom application. To do this, I created a Zap whose trigger was “A new Runkeeper activity”, and authenticated my personal Runkeeper account:
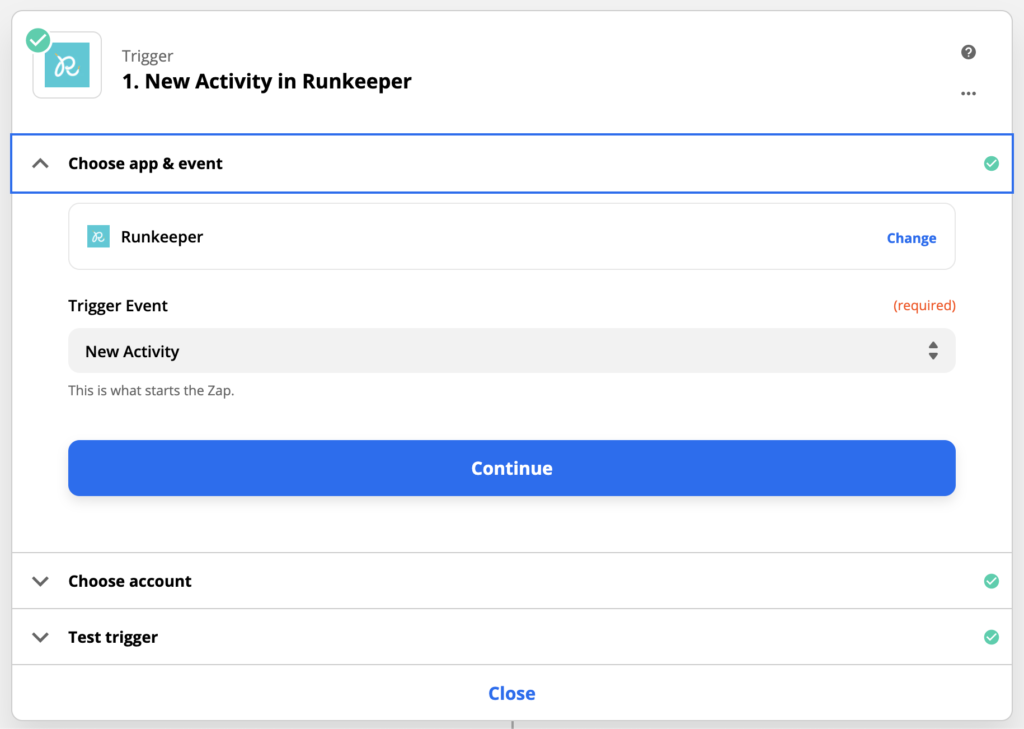
I then added a Zapier step with the Code By Zapier action. This action type gives you a sandboxed NodeJS (or Python) environment that allows you to run arbitrary code.
In my case, this would just be a post request to my app with a JSON payload in the request body, facilitated by the fetch() library which Zapier includes within the Node runtime they provide.
You map the input data (from Runkeeper) to a Javascript variable, then post it to an app server. When finished, the Zapier step looks a bit like this:
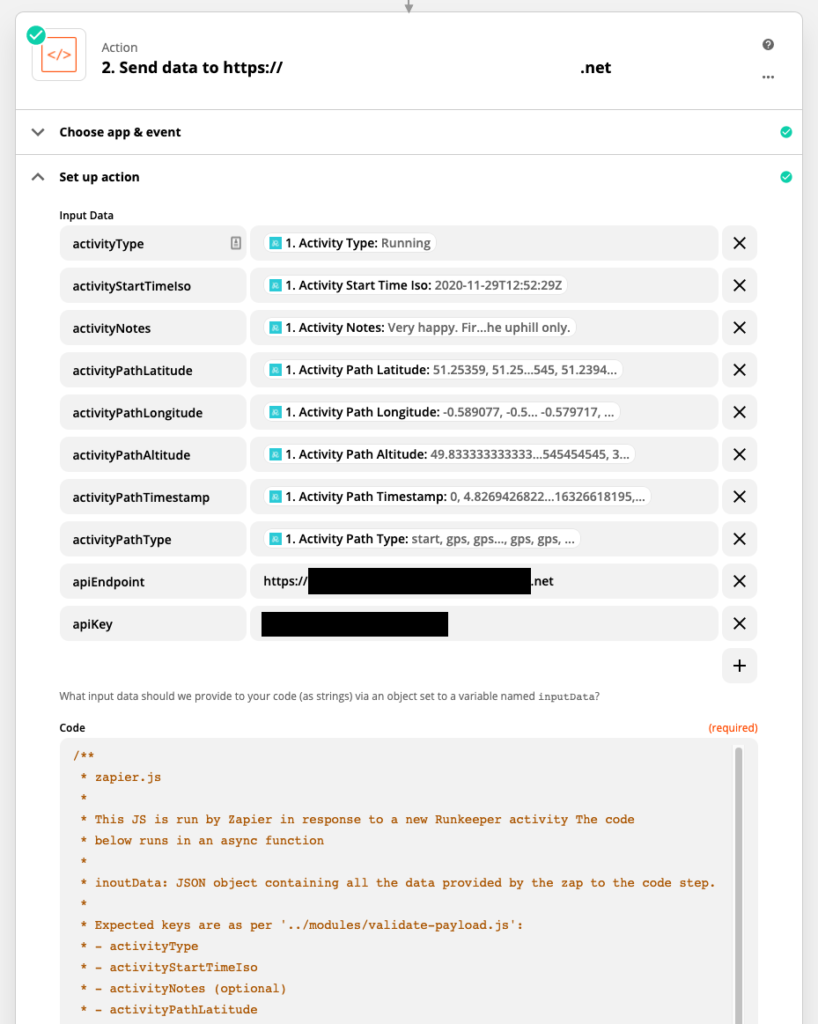
inputData.And here’s a flavour of the fetch() function, which is very simple:
const API_ENDPOINT = inputData.apiEndpoint || null;
const API_KEY = inputData.apiKey || null;
const res = await fetch(API_ENDPOINT, {
method: 'post',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(inputData)
}).catch((error) => {
console.log(error);
});
const body = await res.text();
return {
responseCode: res.status,
body: body
};
Minimising the work that Zapier does was important to me because… I’m frugal. Their Code step imposes a maximum runtime of just 1000ms, in which time your entire function must enter memory and execute.
Zapier offer a much greater runtime limit of 10,000ms on their lowest paid tier but, for an individual, this is not a cheap way to sync Runkeeper and Strava, so I tried to work within the free tier’s bounds.
It’s also important to note that, because of this runtime limit, the server hosting the custom app needs to respond promptly to Zapier. I’ll come back to this point in a minute!
The Custom Application
Once Zapier sends the payload, the custom NodeJS app that I wrote takes over, handling the creation of the Strava activity through a series of simple processes.
I chose to host the app in Microsoft Azure’s App Service, which made it easy to deploy without provisioning or running my own infrastructure with a Node environment. Because the computing requirements are very minimal, I was able to host the app in the free “F1” tier on Azure.
The custom Node app…
- Saves the json payload to disk.
- Responds to Zapier’s HTTP request.
- Queues a function to process the json file at an arbitrary time in the future.
Note that the json isn’t processed synchronously. If the payload looks good, we just tell Zapier that the data will be processed shortly.
I created internal logging for any errors that happen during processing, in case I ever need to troubleshoot a missing activity.
The server processes the JSON by…
- Forming a Javascript object which has an equivalent data structure to a template GPX file.
- Using the
xml2jslibrary to convert the object to valid XML which observes the official GPX schema. - Uploading the GPX file to Strava’s “Uploads” API endpoint.
There aren’t too many complexities in the mechanics of all this. The inbound json data from Runkeeper comes as a comma-separated list of “waypoints”, but there are five separate lists for “waypoint type”, “latitude”, “longitude”, “altitude” and “timestamp”, so you have to trust that the values at any given position of the list all relate to the same point!
I also had to handle the process of refreshing the Strava authentication token if it was expired, which was simply a case of re-authenticating the currently-authenticated user using a “refresh token”. I stored the tokens in a json file in a non-public area of the filesystem, rather than creating a separate data store which would only have been used for the purpose of storing the ephemeral tokens.
Importing My Historical Data
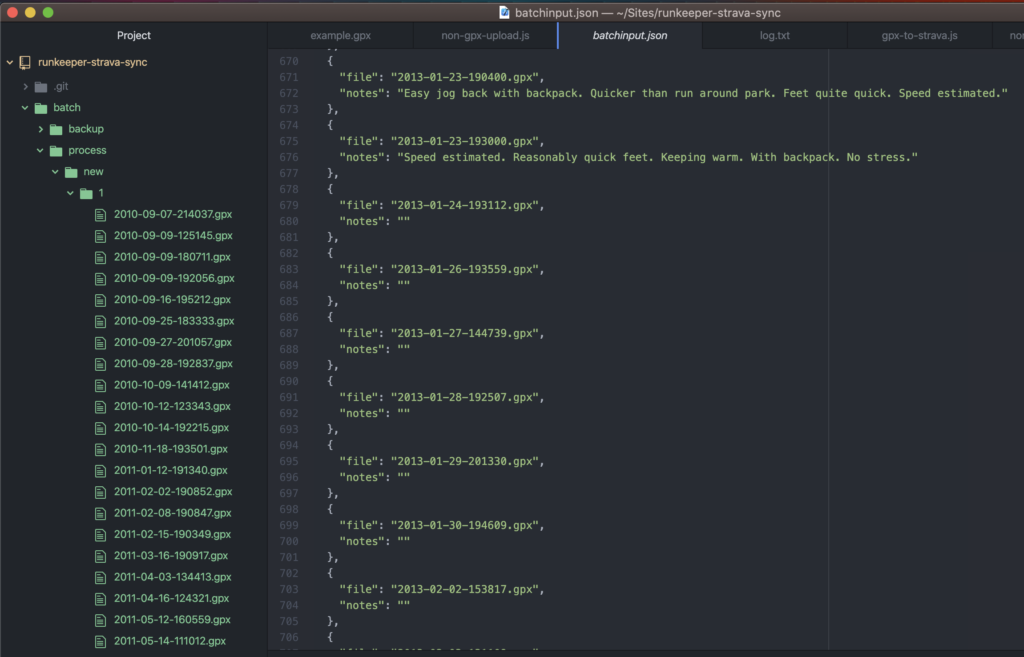
To really cement bragging rights over my running friends, I wrote a batch-upload CLI script to help me ingest all of my historical Runkeeper activity (all 1550 or so exercise activities over 10 years!) into Strava.
Runkeeper’s “Export data” function provided me with a way to download all my historical running data as GPX into a folder on my local machine. The script then sends these GPX files up to Strava’s API.
Because the main app turns the inbound Runkeeper data from Zapier into GPX format before uploading it to Strava, this was as simple as reusing the gpx-to-strava module that I had created for the sync app.
There were only minor challenges, which I was happy to address manually, given that this was a one-off process:
- The GPX data from Runkeeper does not contain an activity
<type>node. - The
<name>of the activity in the GPX file did not match the naming format I had specified in the Sync app. - The Strava API has quotas of 100 calls per 15 minutes and maximum 1000 per day.
I created some one-off scripts to amend the XML nodes in the Runkeeper GPX files to contain data consistent with the main app.
activityType = (function(){
switch(type) {
case 'Run': return 'Running';
case 'Walk': return 'Walking';
case 'Ride': return 'Cycling';
}
})();
newName = moment
.tz(time, "Europe/London")
.format("[" + activityType + " activity on] dddd Do MMMM YYYY [at] HH:mm");
With the API limit, I simply split the files up arbitrarily into folders, and processed the folders one at a time. The batch processing script includes a warning if it looks like you’re going to exceed the 15 minute quota, and with only ~1500 activities this is pretty trivial anyway.
Results
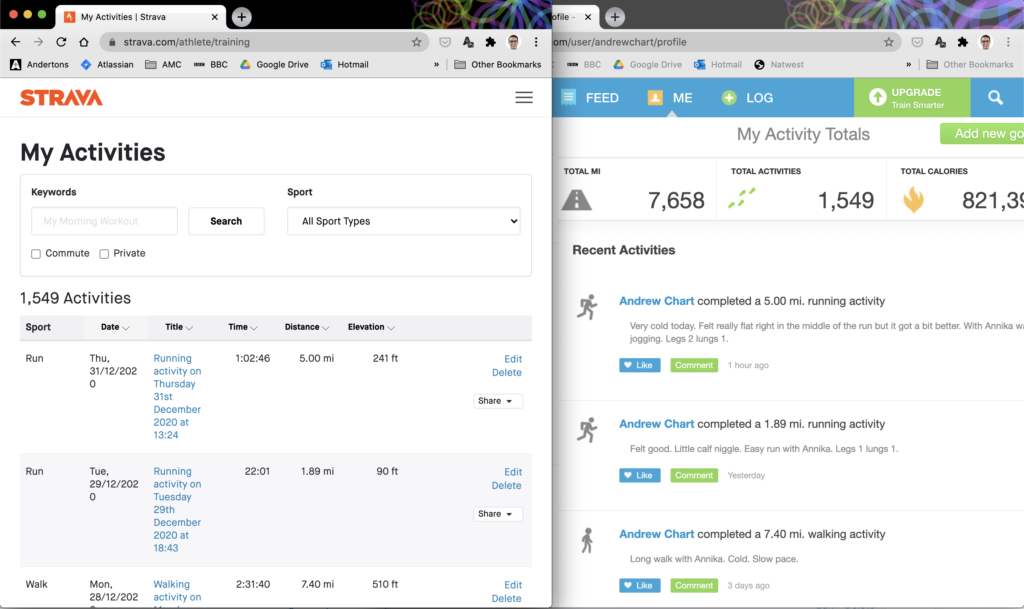
I’m really happy with the results from all of this. Since standing the app up end-to-end I’ve recorded seven activities with zero failures, and managed to get all of my historical activities loaded into Strava successfully. The only disappointing thing is that it doesn’t look like I’m in first place for any segments yet.
There is a minor annoyance which is that my Node server still isn’t responding to Zapier within 1 second every time, despite the constant ‘pinging’. In spite of this, it seems like the payload always makes it from Zapier to the custom app, so I just get a warning that the Zap may have failed. I do wonder if really long activities with many waypoints will require >1000ms execution time, so I might need to look at this again.
I have other ideas for the Sync app which I might explore in future too. For example, the prospect of incorporating temperature data from an external API into the GPX data, or further improving the Zapier step by including a retry mechanism (which, again, is much simpler if you’re willing to pay for Zapier!)
If you want to set up an instance of the connector app for yourself and you need some extra help after reading the repository’s README, please feel free to reach out and contact me and I will do my best to help.